삽입정렬(insertion sort)은 기본적인 제자리 정렬 알고리듬 중 하나로, 배열 내의 어떤 위치의 원소를 해당 배열의 가능한 가장 왼쪽 자리에 ‘삽입’하는 동작을 통해 정렬을 수행한다. 삽입 정렬의 이론적인 성능은 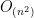
알고리듬
삽입 정렬의 알고리듬 자체는 기본적으로 두 번째부터의 각 원소에 대해서 해당 원소보다 앞에 있는 원소들을 차례로 그 값과 비교해 나가서, 현재 원소가 이동할 수 있는 가장 왼쪽 끝으로 이동시키는 것이다. 그 과정에서 이동해야 하는 구간 사이의 원소들은 모두 오른쪽으로 한칸씩 이동해 나간다.
이렇게 검사하는 위치는 두번째, 세번째,… 마지막 원소에 이르는 식으로 이동한다. 먼저 배열이 다음과 같다고 가정한다.
[45][53][26][93][62][20][33][17]
두번째 원소 53부터 시작하여 앞쪽으로 비교한다. 53의 경우 왼쪽에 43이 더 작은 값이므로 이동할 곳이 없다. 세 번째 원소인 26의 경우를 보자.
[45][53][26][93][62][20][33][17]
~~26 앞에 위치한 53이 더 크다. 따라서 53을 일단 뒤로 민다. 두 번째 위치에서 다시 왼쪽과 비교했을 때 45라는 큰 값이 또 있으므로 45도 뒤로 민다. 그리고 45 자리에 26을 넣는다. 이 동작은 결국, 45, 53을 뒤로 밀고 그 앞에 26을 끼워넣은 동작이다.
[45][53][ ][93][62][20][33][17]
--> 26
# 53을 오른쪽으로 이동
[45][ ][53][93][62][20][33][17]
--> 26
# 45도 오른쪽으로 이동
[ ][45][53][93][62][20][33][17]
26
# 최종적으로 26이 비어있는 0번 인덱스로 이동
[26][45][53][93][62][20][33][17]
이와 같은 방식으로 시작하는 4번째, 5번째,… 이렇게 늘려나가면서 마지막 원소까지 이 동작을 반복하면 모든 자리에 있던 값들이 자신보다 큰 수들의 앞으로 옮겨가면서 정렬된 상태가 완성된다.
삽입 정렬에서 각 원소가 자신의 자리를 찾는 과정을 보면 이미 정렬되어 있는 부분이 많을 수록 원소의 이동이 (왼쪽의 원소를 뒤로 밀어내는) 줄어들게 되는 것을 알 수 있다. 다만 삽입하는 횟수가 적더라도, 삽입을 위해서 큰 원소를 뒤로 밀어내는 과정이 많이 발생하기 때문에 그렇게 효율이 좋은 알고리듬은 아니다. 대신 ‘정렬된 상태에 가까울수록 효율이 좋다’는 특성 때문에 다른 알고리듬과 결합하여 많이 쓰인다. Shell 정렬이 그 예.
이 알고리듬을 그대로 코드로 옮기면 다음과 같다.
from typing import List, TypeVar
T = TypeVar('T')
def insertion_sort_a(xs: List[T]):
# 두 번재 인덱스부터 반복
for i in range(1, len(xs)):
val, j = xs[i], i
# 왼쪽으로가면서 같거나 큰 원소를 오른쪽으로 밀어냄
# 더 작은 원소가 발견되면 멈춤
while j > 0 and xs[j - 1] > val:
xs[j] = xs[j - 1]
j-= 1
# 처음값을 빈 자리에 삽입
xs[j] = val삽입정렬은 최악의 경우
이 때, 삽입할 위치부터 원래 위치사이의 옮겨지는 값들은 모두 연속해 있는 데이터들이다. 따라서 while 루프를 따라 움직이면서 매번 원소를 값을 옮기지 않고, 삽입 위치만 체크한 후 슬라이스를 사용해서 한 번에 옮긴다면 성능을 더 높일 수 있다.
이 아이디어를 적용해서 코드를 다시 쓰면 아래와 같다.
def insertion_sort_v(xs: List[T]):
for i in range(1, len(xs)):
val, j = xs[i], i
while j > 0 and xs[j - 1] > val:
j-= 1
if j < i:
xs[j+1:i+1] = xs[j:i]
xs[j] = val이 코드는 각 원소가 이동할 곳을 찾을 때, 먼저 찾고 이동할 필요가 있을 때에 삽입의 준비동작을 슬라이드 대입으로 가능한 빠르게 처리한다. 아래는 1~200,000 사이의 정수 4,000개 배열에 대해서 두 코드의 성능을 비교한 것이다. 여기서는 조금 차이가 나는 것처럼 보이지만 상황에 따라서는 두 코드가 보이는 성능차이가 크게 다르지 않을 수 있다.
%%timeit
xs = ns[:]
insert_sort_a(xs)
# 1.16 s ± 2.16 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
%%timeit
ys = ns[:]
insert_sort_v(ys)
# 836 ms ± 3.52 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)