파이썬으로 이진 탐색 구현하기

이진 탐색(binary search)은 정렬된 데이터에서 특정한 값을 아주 빠르게 찾는 방법이다. N개의 데이터 중에서 특정한 값 x를 찾을 때, 최악의 경우 N번의 비교가 필요한데, 이진 탐색의 경우 최대 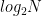
이진 탐색의 원리
이진 탐색은 정렬된 데이터에서 특정한 지점을 기준으로 보다 작은 값들은 왼쪽에 있고, 보다 큰 값들은 오른쪽에 있다는 성질을 이용한다. 먼저 전체 데이터의 중간에 있는 값과 찾고자하는 값을 비교한다. 중간에 있는 값이 더 크다면, 찾으려는 값은 그 왼쪽에 있을 것이라고 예측할 수 있다. (즉, 오른쪽에는 절대 존재하지 않는다.) 다시 왼쪽 절반에서 중앙에 있는 값을 찾아서 다시 찾고자 하는 값과 비교해본다. 이런식으로 대상 값이 있을 구역을 매 비교마다 절반의 크기로 줄여나가면서 값을 찾아나간다. 최종적으로 해당 값을 찾거나, 혹은 구역의 크기가 0이되면 탐색을 종료한다.
이진 탐색 구현하기
- 처음 시작은 리스트의 전체 구역 (0에서 리스트 길이까지)을 대상으로 잡는다.
- 구역의 중간점에 해당하는 원소를 찾는 값과 비교한다. 만약 일치한다면 해당 인덱스를 리턴한다.
- 중간 원소의 값이 더 크다면 찾으려는 값은 구역의 왼쪽 절반에 있을 것이다.
- 중간 원소의 값이 더 작다면 찾으려는 값은 구역의 오른쪽 절반에 있을 것이다.
- 3, 4의 결과에 따라서 구역의 시작값과 끝값을 바꾸면서 계속 찾는다. 만약 구역의 길이가 0이면 -1을 리턴한다. (값이 없음)
코드는 재귀로 구현하기 딱 좋지만, 간단하게 while 루프로 표현할 수 있다. 이진 탐색을 실행하는 함수 binsearch()는 다음과 같이 작성된다.
def binsearch(xs, x):
a, b = 0, len(xs)
while True:
if a == b: # 구간의 길이가 0이면 값이 없음
return -1
c = (a + b) // 2
if xs[c] == x:
return c
if xs[c] > x: # 구간을 왼쪽 절반으로 줄임
a, b = a, c
else: # 구간을 오른쪽 절반으로 줄임
a, b = c + 1, b
이 코드는 다시 조금 더 짧게 다음과 같이 정리할 수 있다.
def binsearch(xs, x):
a, b = 0, len(xs)
while a < b:
c = (a + b) // 2
if xs[c] == x:
return c
a, b = (a, c) if xs[c] > x else (c + 1, b)
return -1선형 탐색과의 비교
간단한 예를 통해서 선형탐색과 비교를 해보자. 10만개짜리 난수 배열에서 특정한 값을 찾는 시간을 알아보자.
from random import randint
xs = [randint(100, 1_000_000) for _ in range(100_000)]
ys = sorted(xs)
k = randint(100, 1_000_000)
# -------------------------------
%timeit xs.index(k)
# 5.3 ms ± 119 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
# -------------------------------
%timeit binsearch(ys, k)
# 4.03 µs ± 57.2 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
0.005초 대 0.000004 초로 이진 탐색쪽이 훨씬 빠르다.
이진 탐색으로 정렬하기 – insort
이진 탐색의 원리를 사용하면 정렬된 리스트에 값을 추가할 때, 정렬된 상태가 되도록 값을 추가할 수 있다. 중앙값이 새 값보다 작거나 같다면 중앙값의 오른쪽에서 새 위치를 찾고, 반대로 더 작다면 중앙값의 왼쪽에서 새 위치를 찾는다. 새 위치를 찾는 구간의 길이가 0이면 그 위치에 원소를 삽입하면 된다.
이 성질을 이용하면 중간에 원소를 끼워넣는 비용이 작은 자료구조라는 전제하에 데이터를 비교적 빠른 시간 내에 정렬할 수도 있다.
def insort(xs, x):
a, b = 0, len(xs)
while a < b:
c = (a + b) // 2
a, b = (a, c) if xs[c] > x else (c + 1, b)
x[a:a] = [x]
# 난수 리스트 정렬
xs = [(randint(100, 1000), i) for i in range(50)]
ys = []
for x in xs:
insort(ys, x)테스트를 해보면 알겠지만, 이 정렬은 크기가 같은 값이 이미 있을 때 그 오른쪽으로 값이 추가되기 때문에 xs -> ys로의 정렬은 안정적이다. (검색에서 안정적(stable)이라는 것은 중복되는 둘 이상의 원소가 정렬된 후에도 처음의 순서를 유지하는 것을 말한다.)
예전에도 소개한 적이 있지만, 파이썬은 이진 탐색 알고리듬을 구현한 bisect 모듈을 제공하고 있다. 파이썬의 bisect 모듈은 순수한 파이썬으로 구현되어 있으니 참고해보는 것도 좋을 것 같다.

