30명의 사람이 있을 때, 이 중 생일 같은 사람이 최소 2명 있을 확률을 구하고 싶다. 어떻게 계산할 수 있을까? 이러한 문제를 생일 문제라 한다. 흥미로운 점은 생일 문제가 우리의 직관을 비웃는 것 같은 결과를 보인다는 것이다.
예를 들어 당신이 누군가를 만났다고 하자. 그 사람이 당신과 생일이 같을 확률은 얼마일까? 당신의 생일이 정해져 있으므로 그 사람의 생일은 365일 중 같은 날인 하루여야 한다. 이 때의 확률은 1/365로 약 0.274% 밖에 안된다. 이처럼 1년의 날 수가 365일이나 되기 때문에 생일이 같아질 확률이 매우 작아 보인다.
다시 문제로 돌아와보자. 30명의 사람이 있을 때 생일이 같은 사람이 최소 2명 있을 확률은 2명이 같을 때, 3명이 같을 때, … 30명이 모두 같을 때의 경우를 모두 찾아야 하므로 쉬운 일이 아니다. 따라서 전체 확률 공간에서 모든 사람이 생일이 다른 확률을 제외하는 식으로 찾아야 한다.
30명 중 한 명의 생일을 선택했고, 두 번째 사람의 생일이 그 사람과 다를 확률은 364/365이다. 같은 식으로 이미 채택된 생일을 제외하고 남은 날 중에 생일이 있을 확률들은 363/365, 362/365… 이다. 이 모든 경우가 동시에 발생해야 생일이 겹치는 날이 없으므로 생일이 겹치지 않은 확률의 계산은 다음과 같이 계산된다.

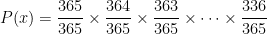
이는 조금 간단히 쓰면


시뮬레이션을 통해서 검증해보자. 365개 숫자 중에서 30개를 뽑아서 중복이 없는 경우의 횟수를 센다. 이걸 10,000 회 반복해서 겹치지 않는 경우에 대한 통계적 확률을 뽑아보자.
from random import randint
def f(k=10000):
r = 0
for _ in range(k):
s = set()
for _ in range(30):
s.add(randint(1, 365))
r += 1 if len(s) == 30 else 0
return r / k
for _ in range(10):
print(f'p={f():.2%}')
------------------------
p=29.34%
p=28.91%
p=28.82%
p=29.00%
p=29.83%
p=29.52%
p=29.49%
p=29.34%
p=29.54%
p=28.83%얼추 29% 언저리에 나오는 것을 볼 수 있다. 이번에는 인원수에 따라서 생일이 같은 사람이 있을 확률을 계산하는 코드를 작성해서 인원수에 따라서 이 확률이 어떻게 변하는지 알아보자. 셈을 간단히 하기 위해 리스트에 있는 모든 값을 곱하는 product 함수를 정의하고 이를 계산식에 사용한다.
from functools import reduce
product = lambda xs: reduce(lambda x, y: x * y, xs, 1)
def p_same_birthday(n=30):
return 1 - product((x+1)/365 for x in range (365-n, 365))결과는 놀랍다. 비둘기집 원리에 따르면 366명이 있을 때 생일이 같을 확률이 100%가 된다. 하지만 실질적으로는 20명 정도만 되어도 이미 확률이 절반가까이 되며 100명이 되면 99.99997%가 된다. 이론적으로 완전한 100%는 366명째일 것이나 사실상 100명이 되면 생일이 같은 사람이 거의 있을 것이라 볼 수 있다. 200명이 되면 이 확률이99.9999999999999999999999999998%에 달한다. (아이고 의미 없다.)
# 소수점 6째자리에서 반올림
2 -> 0.27397%
3 -> 0.82042%
4 -> 1.63559%
5 -> 2.71356%
...
10 -> 11.69482%
20 -> 41.14384%
30 -> 70.63162%
40 -> 89.12318%
50 -> 97.03736%
60 -> 99.41227%
70 -> 99.91596%
80 -> 99.99143%
90 -> 99.99938%
100 -> 99.99997%
110 -> 100.00000%다만 이것이 ‘우리반이 30명일 때 나와 생일이 같은 친구가 있을 확률’을 말하는 것은 아니다. 이 때에는 비교되는 날짜의 내 생일 하루로 고정되므로


참고로 생일이 겹치는 것과 비슷하게 해시값이 같은 두 입력값이 있을 확률 역시 입력값의 개수가 많아질 수록 비슷하게 매우 빠르게 증가하기 때문에 모든 입력값에 대해 계산하지 않고도 해시 충돌을 찾을 수 있다고 한다. (참고)